Integrating ChatGPT into an existing high-traffic Ruby on Rails poses two main challenges: ensuring the server can handle increased query loads and securing API tokens from exposure. OpenAI's API requires that each request includes an API token which must be kept secure, and requests can take several seconds to process. In our particular use case, running these requests on our server would tie up roughly 300mb of memory per thread for 3 seconds per request – that's more than 10 times slower than our next slowest request.
Our best case solution will address this load imbalance by offloading the "waiting for response" step to the client's side, but to do so we need a mechanism to avoid leaking our API token to the world.
Solutions that don't work
We've considered and discarded several potential solutions before finding an approach that works.
1. Background threads
Rails has ActiveJob for background processing where we want to avoid blocking a client request. Moving the AI service call to a background job would certainly avoid tying up a user process, it will also move it off the webserver's thread. However, this doesn't address the fundamental problem – it's not the user waiting that's the issue here, the user is expecting to wait as they know they're interacting with an AI. The issue we're addressing is not the client waiting, but the server – we don't want to spend our precious AWS credits on 300mb of resident memory that's just waiting for a response from OpenAI. Moving to a background job doesn't address this, and it introduces a new problem – what's to stop someone from overloading our servers with background jobs? Now we have to implement some form of back pressure.
2. Non-blocking IO
Lots of languages have lightweight ways to park a request that's waiting on IO until there's a response to process. Ruby introduced Ractors for precisely this purpose. Unfortunately, Rails hasn't reached the point where this is a viable option – support may be coming, i.e. Falcon, but community discussions suggest that if you're using ActiveRecord it's not there yet. We did a prototype and found that a number of libraries we depend on don't support non-blocking IO yet, and while this might be a viable alternative for specific niches, for our legacy app this was a non-starter.
3. Side-car webserver
In our enthusiasm to explore Ruby NIO, we added Falcon to our docker containers and used NGINX to route AI requests to Falcon, which then verified client sessions by calling Rails internally. This approach worked, but it's a lot of extra complexity.
Solution: Proxy Microservice for AI Queries
In our internal discussions, we realised that the solution we're looking for already exists – when we load documents from ActiveStorage we don't proxy all of that data through Rails, rather, S3 generates a signed URL and we redirect the user's browser to retrieve the resource from S3 directly.
This mechanism seems entirely appropriate for OpenAI queries, to the point that we couldn't quite believe that the solution didn't already exist. We quickly discovered that we're not the only ones who've had this realisation – and fortunately it's already been productised by Signway as a general purpose tool for offloading slow LLM requests.
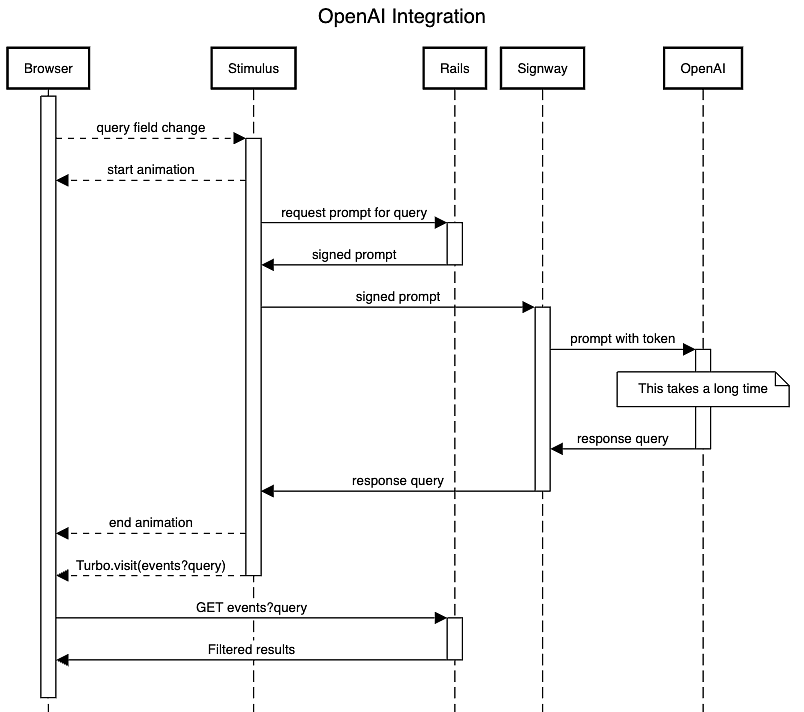
Signway is a proxy microservice dedicated to handling interactions with LLM APIs, (OpenAI in our case). This service acts as an intermediary, receiving signed requests from the client and forwarding them to the API. This design offloads the request from the server to the client's browser while keeping the API token secure. When Signway receives a request it verifies that the request is correctly signed and has not expired using the same algorithm as S3. If the request is valid then it adds the API bearer token and forwards the request to OpenAI.
We demonstrated proof of concept using Signway to proxy requests from an "gpt-enhanced search" integration where a Chatbox translates a user's query into get params for a complex Rails index page. Users can input their queries in natural language, and the AI service processes these queries and returns structured query parameters based on a JSON description of the available filter options.
OpenAI advanced search with Signway
While we could implement something like this for ourselves, Signway has already productised this and their Github repo includes detailed examples. Our interactions with the Signway team were very positive, and we were able to take our proof-of-concept integration that embedded the OpenAI token and replace it with signed URLs within half an hour, including reading the documentation. The integrated pipeline worked on the first try!
Before integration, exposing our API token to the client (don't do this!):
Conclusion: Use Signed Requests for Efficient AI Integration
Using a proxy micro-service with signed requests has all of the hallmarks of an elegant solution to the LLM integration problem – load scales with query volume, not AI response time, and signed requests ensure secure handling of API tokens.
We hope that OpenAI and other LLM vendors will soon add support for signed requests themselves, but in the mean time it's good to have an option that doesn't require re-architecting our stack.